Imagine you are the owner of a modest grocery store in your neighborhood. You know most of your customers in person, and you do a pretty good job fulfilling their demands. After a while, your hard work pays off, and now, you open three new branches in different neighborhoods. It is hard to stay on top of the needs of four stores, but thanks to more coffee and less sleep, you still rock. Then one day, you achieve a milestone and open your tenth store. How to analyze the requirements of so many stores? What if you have dozens of stores? Hundreds? Thousands? Could you still succeed in staying connected with your customers and figuring out similarities and differences in product preferences, lifestyles, and purchasing power across all locations?
Let’s reframe the case. Is it wise to plan by overall numbers or averages when you are the head of an enormous chain store? As a known fact, mean values tend to hide variances across different parts of the business. That kind of general information can only signal a major problem and usually hides opportunities.
So how to measure the performance of stores? Ordering by a metric and comparing the best and worst might also be useless most of the time since they probably have different dynamics. For example, one store is in the center city while the other is in a suburb, and hence they cater to a different customer base with vastly different purchase patterns and buying power. Now the question is how to find stores that have similar dynamics. Here comes Cluster Analysis for help!
What is Cluster Analysis?
To put it all in simple terms, cluster analysis is a method that groups object according to their similarities. These similarities are measured by some predefined attributes such as the shopping behavior of customers (market basket size), sales performance (revenue per week), price preferences (average sales price), store traffic, etc.
If the case is customer segmentation, then customers will be your objects. Your possible attributes will be all information you can gather from customers (demographics, shopping frequency, buying history, etc.). After selecting the relevant attributes and clustering method, analysis can be applied to the data.
Although applying clustering seems so easy, results probably will be unsatisfying or lead to wrong inferences if some key points are not regarded. Some of them are listed below.
1. Choosing an Appropriate Method
There are many methods to define clusters. The methods generally require some parameters to be defined in advance. In addition, the method has to be relevant to the issue and data. Thus, the details of the methods have to be known by practitioners.
2. Irrelevant Attributes:
Using an attribute that is not relevant to the problem will burden the calculation time of the analysis while it lowers the quality of the analysis.
3. Curse of Dimensionality:
Although you weed out irrelevant attributes, you might still have many attributes which you cannot dare to leave out. Using a high number of attributes has some undesired results.
4. The difficulty of visualization:
It is hard to create a comprehensible display when your data includes more than three attributes since each attribute uses a dimension.
5. Increasing time of computation
Each extra attribute increases the time of calculation.
6. Overfitting
As the number of attributes increases, learning systems tend to memorize. In this case, two very similar clusters might be generated, while it could be better if it behaved as a single cluster.
7. Outliers
Outliers issue is Achilles’ heel for not only clustering but also other learning systems. Outliers might cause either many clusters with few observations or a few clusters with dissimilar observations. Treatment of outliers has to be decided in advance; for example, will you remove outliers or use a different algorithm robust to outliers?
8. Evaluation of Results:
It is equally or more important than conducting the analysis. There are many statistical methods to evaluate the clustering results. The selection of the evaluation method depends on the problem, data, and clustering method. Besides, evaluation has to be also made in the aspect of business concerns.
Business Applications
In business applications, clustering analysis is generally used as a preprocessing step. The analysis can be conducted before Assortment Planning, Promotion Planning, or Markdown Optimization.
Customer segmentation which we discussed above, might be an initial step for a promotion planning project. You can offer customized promotions to your customer segments by knowing their expectations.
Another example is Store Clustering for assortment planning. Supplying the right products to the right customers is crucial for retail chains. Without store clustering, you cannot define the needs of your stores (or their customers). You can provide localized assortment plans according to a cluster of your stores.
For Store Clustering, you need to take a few key considerations into account. Deciding on which features to be used is critical. Store location, store type, and demographics of customers are some of the attributes that can be used. However, in many cases, using store attributes might not be sufficient. Clustering stores based on the sales performance of product categories is a well-known method for store clustering. In this method, stores are grouped for each product category according to the similarity of sales trends of that category.
Beyond a Simple Clustering Analysis
Clustering is a tough issue, which has many details to be considered. Since it is applied as an initial step, misapplication might cause the false implementation of further analysis. Thus, professional help can improve the quality of analysis and plans immediately. Here is a list of features that Solvoyo customers benefit from:
- Selection of the best feature set and clustering method for the business case
- Technically optimal analysis (Avoidance of curse of dimensionality, outliers, overfitting)
- Easy integration of clustering with other tools (Assortment planning, markdown optimization)
- Dynamic change of attributes by the user
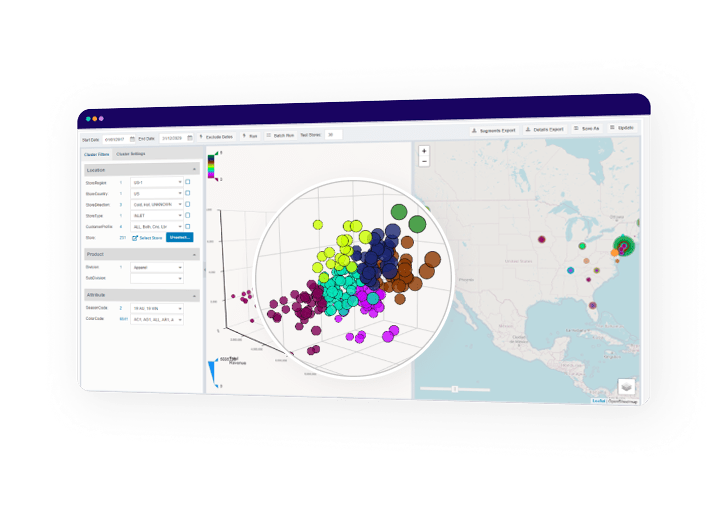
- 3D and Location-based visualization of clusters
- Overriding of recommended clusters
The Solvoyo Platform offers state-of-the-art clustering analytics for retail’s best practices:
- Selection of the most suitable attributes, feature set, and clustering method for each case
- Optimal-seeking methods, dealing successfully with the curse of dimensionality.
- Interactive what-if analysis of the results
- Advanced but intuitive visualization of the clusters
Solvoyo is a Gartner-recognized vendor that supports integration with many commercial 3rd-party ERP systems as well as homegrown systems. Our clustering capabilities support our other services that range from Demand and Supply Planning to Store Replenishment.